
🔥 Introduciendo PrecisaDashboard
Abrimos al público la primera versión Beta de PrecisaDashboard, con tendencias electorales históricas, matrices de transferencia y perfiles de los partidos.

Presentamos PrecisaDashboard (v1-Beta), una herramienta para explorar las tendencias de voto, perfiles de los partidos y transferencias, con una interfaz sencilla e intuitiva pero que se construye a partir de una metodología propia que se basa en técnicas de computación avanzadas como machine learning.
Desarrolladores: Roke A. Masso y Endika Nuñez

Índice de contenidos:
Qué es PrecisaDashboard
Es una herramienta interactiva que permite explorar tendencias de opinión pública para las elecciones generales a lo largo de las última décadas.
⚠️ Es una herramienta en proceso de desarrollo (v1-Beta). Si encuentras alguna incongruencia en los datos o alguna funcionalidad que no está dando los resultados esperados, no dudes en ponerte en contacto con nosostros.Objetivos
El principal objetivo de PrecisaDB es proporcionar a los usuarios datos consistentes y confiables a lo largo de las últimas décadas para poder analizar con rigor las tendencias de la opinión pública y brindar una visión clara y completa de la evolución de la política española.
Datos y fuentes
PrecisaDB se alimenta con datos abiertos del Centro de Investigaciones Sociológicas (CIS), institución pública encargada de realizar estudios y encuestas sobre opiniones y comportamientos políticos en España.
Trabajamos específicamente con los microdatos que el CIS publica de manera abierta —procesados y analizados utilizando nuestra metodología propia— lo que nos permite acceder a información detallada y granular sobre las preferencias de voto y otras variables relevantes.
Actualmente, tenemos procesados más de 400 barómetros mensuales (+1.000.000 de entrevistas) y preelectorales de ámbito estatal, con más de 80 variables sociodemográficas, geográficas, educativas, laborales, religiosas, socioeconómicas, culturales, ideológicas, de comportamiento electoral y actitudes hacia la política y la economía.
A lo largo de todo el proceso también utilizamos otras fuentes de datos públicos, como los resultados electorales recogidos desde el Ministerio del Interior, datos del padrón continuo del Instituto Nacional de Estadística (INE), así como fuentes de información auxiliares del propio CIS, cómo ficheros de registros o cuestionarios.
Funcionalidades destacadas
El dashboard ofrece una serie de funcionalidades destacadas que lo diferencian de otras herramientas disponibles en el mercado.

Se pueden visualizar y explorar tendencias electorales históricas de forma completa y accesible.
Gracias a nuestra metodología propia, podemos sortear los cambios de criterios que han surgido en las encuestas del CIS a lo largo de los años. Utilizar el mismo proceso metodológico permite analizar y comparar los datos electorales en diferentes periodos y hacer una interpretación más precisa y consistente de las tendencias políticas.
Los usuarios pueden explorar tendencias electorales particulares en diferentes segmentos de la población, como edad, género, nivel educativo o ubicación geográfica. Esta función permite identificar patrones y comprender mejor los diferentes factores que influyen en los resultados electorales.
Usabilidad y accesibilidad
PrecisaDB hemos diseñado pensando en la usabilidad y accesibilidad para brindar una experiencia fácil y accesible a todo tipo de usuarios. Ofrecemos opciones de personalización para adaptarse a las necesidades individuales de los usuarios, permitiéndoles seleccionar periodos de tiempo, regiones geográficas y variables específicas. Con una interfaz intuitiva, nos aseguramos de que todos los usuarios puedan explorar las tendencias electorales de manera fácil y cómoda, sin importar su nivel de experiencia o habilidades.

Próximas actualizaciones
En PrecisaResearch estamos trabajando en la incorporación de nuevas secciones y funcionalidades. A continuación identificamos algunas de ellas:
Nuevas secciones
Estimación de voto y escaños desgranado por circunscripción
Conocimiento, valoración y escala ideológica de los líderes políticos y ministros
Principales problemas personales y generales
Comportamiento electoral de los indecisos
Detalles muestrales y metodológicas para ahondar en mayor transparencia
Nuevas funcionalidades
Capacidad de agregar mayor muestra ampliando el estudio a más de un barómetro, y poder escoger el peso que cada estudio debería tener
Funciones para descargar gráficos y datos, además de una API para hacer llamadas concretas y obtener los microdatos ya procesados
Realizar cruces de variables con mayor granularidad
Nuevos modelos y técnicas
Modelo de participación electoral
Ténicas novedosas como el Multilevel regression with poststratification (MRP) para evaluar el comportamiento electoral en escalas desagregadas
Nuevas fuentes de datos
Ampliar el estudio a distintos ámbitos como las redes socialiales, audiencias de los medios de comunicación, exploración de datos a partir de la Encuesta de Condiciones de Vida (INE), y muchas otras posibilidades que se abren
Posibilidad de poder procesar información externa con los algoritmos y técnicas utilizadas en PrecisaDB para realizar labores de contraste
Metodología
A continuación explicaré de forma breve (escribiré un artículo detallado más adelante, con la publicación de la versión definitiva) el proceso metodológico que seguimos hasta llegar a los datos que visualizaras en PrecisaDB.
Este es el esquema del proceso metodológico, que consta de 6 pasos principales:
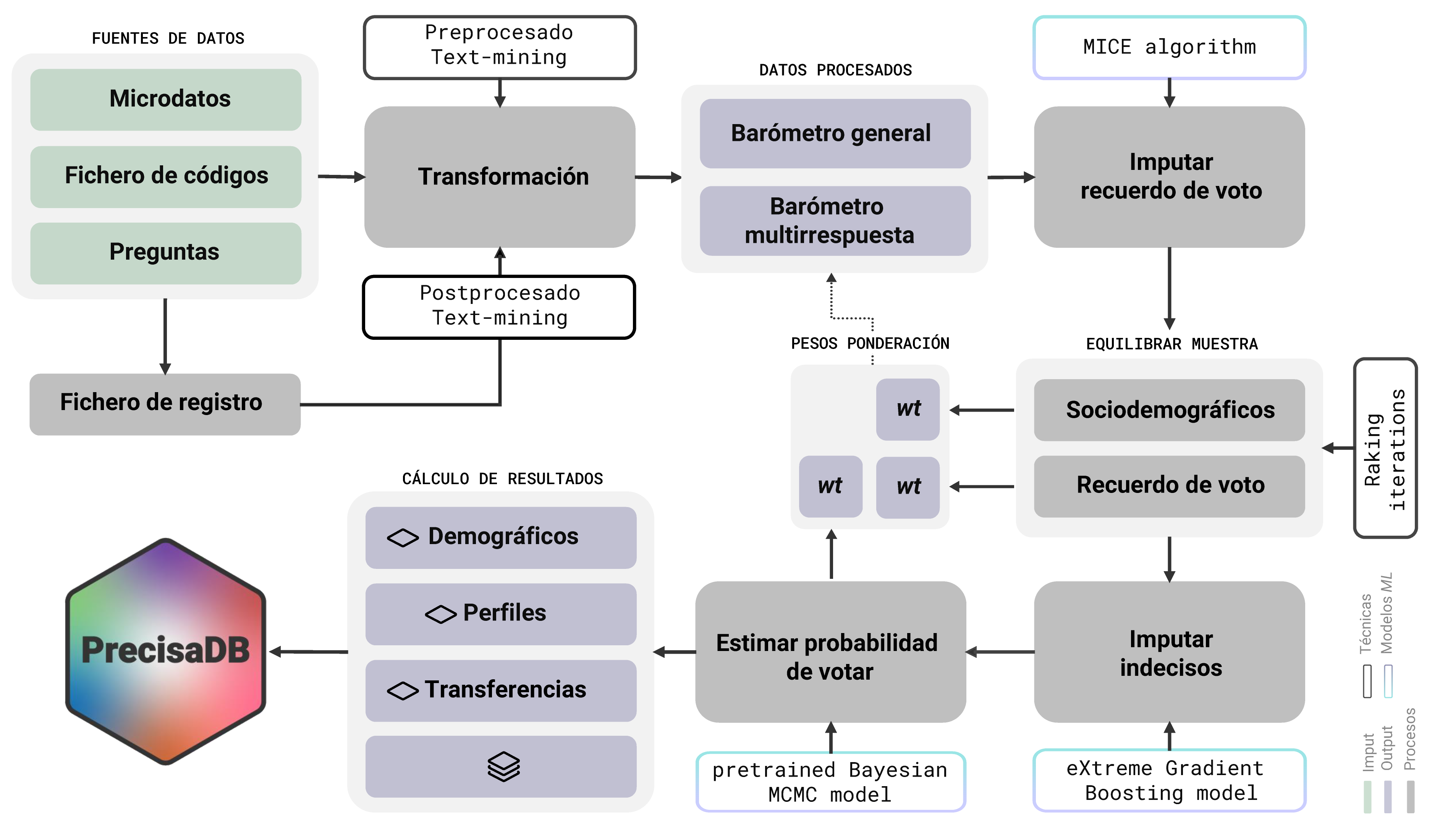
Procesamiento de datos: Se recopilan y procesan datos de diversas fuentes, como he mencionado anteriormente. Procesamos archivos CSV y SAV, pero también ficheros de registro en formato PDF. Utilizamos un algoritmo diseñado internamente para dar la misma estructura de datos a cada uno de los estudios del CIS.
Para lograr esto, aplicamos técnicas avanzadas de text-mining avanzado (limpieza de datos, detección de sintaxis…) y modelado supervisado (incorporación de base de datos propia, elaborado manualmente, que sirve al algoritmo para establecer patrones e identificar variables relevantes en futuros estudios).
Una vez que hemos estructurado los datos, obtenemos los barómetros generales y los barómetros multirespuesta (donde el entrevistado tienen que dar más de una respuesta a cada pregunta, por ejemplo, principales problemas o escala de valoración de líderes políticos).
Imputación de recuerdo de voto: Utilizamos la técnica de MICE (Multiple Imputation by Chained Equations) y método Ranger (un algoritmo de aprendizaje automático o machine learning utilizado para problemas de clasificación y regresión basado en la técnica de bosques aleatorios o Random Forest) para imputar los valores vacíos en la variable recuerdo de voto.
MICE es un enfoque basado en modelos estadísticos que utiliza una cadena de ecuaciones condicionales para estimar los valores faltantes y se realiza utilizando múltiples variables sociodemográficas.
Equilibrado de la muestra: Equilibramos la muestra por variables sociodemográficas cruzadas que se encuentran en el padrón continuo, como el sexo, grupos de edad y el territorio.
También ponderamos la muestra por recuerdo de voto —uno de los principales sesgos de los barómetros del CIS— utilizando los resultados electorales oficiales como referencia. Esta etapa se realiza mediante el método de imputación conocido como raking, que busca los pesos que mejor se ajustan de forma iterativa para asegurar que la distribución de las variables en la muestra se ajuste a la distribución poblacional conocida.

Imputación de indecisos: Una vez que hemos imputado y equilibrado los datos, utilizamos un modelo de machine learning llamado eXtreme Gradient Boosting (XGBoost) para estimar la intención de voto de los indecisos. XGBoost es un algoritmo potente que utiliza una combinación de árboles de decisión y boosting para realizar predicciones precisas. El modelo de aprendizaje automático se basa en un proceso de búsqueda en cuadrícula (grid search) que sirve para encontrar los mejores hiperparámetros en cada caso y utiliza la validación cruzada (cross-validation) para evaluar y comparar su rendimiento.
La imputación se realiza para cada barómetro individualmente y el modelo se entrena con los votantes no-indecisos para predecir el comportamiento electoral de los que no tienen decidido su voto. Para ello se utilizan decenas de variables sociodemográficas y de actitudes hacia la política.

Es un modelo similar al que utiliza Centre d'Estudis d'Opinió (CEO), cuya trabajo y transparencia es especialmente reseñable.
Estimación de la participación individual: Por último, utilizamos un modelo de machine learning bayesiano llamado MCMC (Markov Chain Monte Carlo) para obtener la probabilidad de voto de cada individuo y estimar la participación electoral. El modelo MCMC utiliza métodos de simulación y muestreo para obtener estimaciones probabilísticas.
A diferencia de la imputación de indecisos, este modelo está preentrenado. El preentrenamiento del modelo con la base de datos histórica (con especial atención puesta en los barómetros preelectorales) nos permite capturar las relaciones y patrones subyacentes entre las variables independientes y la probabilidad de votar de cada entrevistado. Utilizamos un modelo preentrenado debido a la ausencia de la variable “escala de probabilidad de votar (0-10)” en muchos barómetros del CIS. Por tanto, el modelo se entrena con todos los barómetros que incluyan esta información y predice la probabilidad de participar de cada individuo en cualquier nuevo estudio. Este modelo tiene 2 virtudes:
Las probabilidades son individuales, por lo que nos permite conocer qué segmentos de la población (por edad, ideología o renta, por ejemplo) son más proclives de ir a votar.
Es un modelo probabilístico, por lo que los resultados que arroja están sujetas a una distribución de la probabilidad. Esto es, ofrece distintos escenarios de participación.


✨ Actualmente, el modelo de participación está en fase de validación y test por lo que los datos que se muestran en el dashboard no utilizan los pesos de participación estimados por el modelo.
En PrecisaResearch estamos trabajando en distintos modelos de partición, por lo que no descartamos usar varios modelos ensamblados en las futuras actualizaciones.Cálculo de resultados: Una vez que hemos completado todos estos pasos, calculamos los resultados que se pueden explorar en el dashboard, lo que incluye visualizaciones de tendencias electorales, análisis comparativos y otras métricas relevantes.
Nuestra metodología y el uso de técnicas avanzadas de computación nos permiten ofrecer datos confiables y precisos para el análisis de tendencias electorales a lo largo del tiempo.
Invitación a explorar
¡Te invitamos a explorar PrecisaDashboard! Obtén una visión profunda de las tendencias a lo largo de los años, filtra datos según tus preferencias y desentraña patrones significativos en el panorama electoral.
Simplemente pulsa el siguiente botón e inicia sesión para acceder a PrecisaDB.
Si tienes cualquier duda, sugerencia o estás interesado en una herramienta tecnológica como esta, ponte en contacto con nosotros pinchando en este enlace o a través de nuestra cuentas de Twitter (Roke A. Masso y Endika Nuñez).
¿Te interesa esta herramienta? Déjanos tu valoración aquí: